This post is a continuation of the blog where I discussed using U-SQL to standardize JSON input files which vary in format from file to file, into a consistent standardized CSV format that's easier to work with downstream. Now let's talk about how to make this happen on a schedule with Azure Data Factory (ADF).
This was all done with Version 1 of ADF. I have not tested this yet with the ADF V2 Preview which was just released.
Prerequisites
- Steps 1-4 from my previous post, which includes registering the custom JSON assemblies, creating a database in the Azure Data Lake Catalog, and uploading our raw file so it's ready to use.
- An Azure Data Factory service provisioned and ready to use (this post reflects ADF V1), along with some basic knowledge about ADF since I'm not going into ADF details in this post.
Summary of Steps
- Create a procedure in the ADL catalog
- Test the procedure
- Create a service principal (aka AAD App) [one time setup]
- Assign permissions to service principal [one time setup]
- Obtain IDs [one time setup]
- Create ADF components
- Verify success of ADF job
Step 1: Create a Procedure in the ADLA Catalog Which Will Be Executed By ADF
This ADLA procedure will be executed by Azure Data Factory. Alternatively, you could also reference a U-SQL script in Azure Storage if you prefer storing a script file there (at the time of this writing, we cannot yet store a script file in ADLS). Either way, U-SQL scripts are typically just too long to practically embed in the Azure Data Factory pipeline activity. In addition to what was discussed in the first part of this solution, we want this stored procedure to:
- Reference 'external' variables which will be populated by the ADF time slices (in our case, the time slice is daily)
- Apply the ADF time slices to the 'where' predicate
- Use variables to create a "smart" output file path & name which allows the standardized output partitioning to match the raw data partitioning by year/month/day
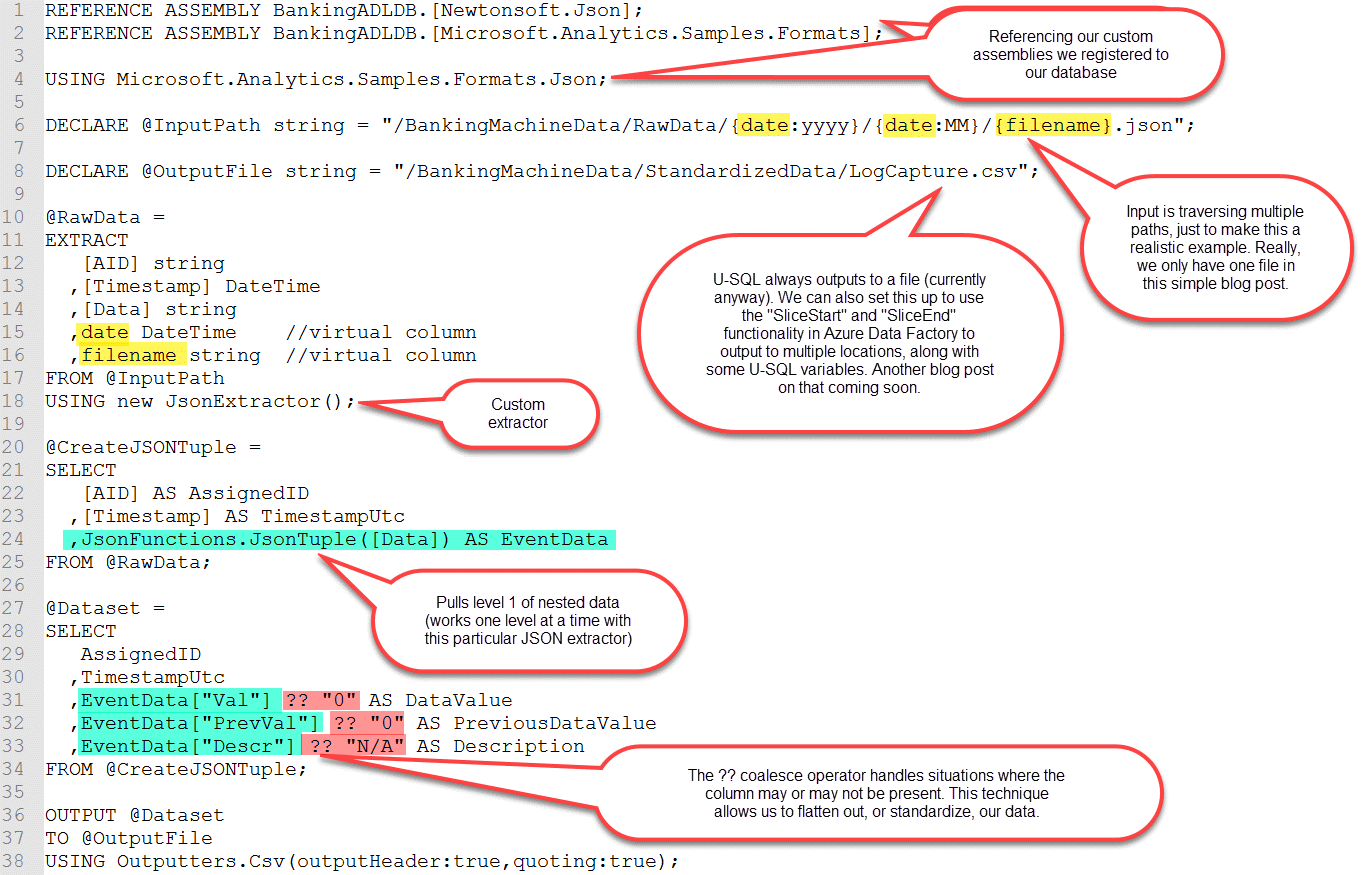
Run the following U-SQL (Azure Data Lake Analytics) job:
CREATE PROCEDURE BankingADLDB.dbo.uspCreateStandardizedDataset(@DateSliceStart DateTime, @DateSliceEnd DateTime)
AS
BEGIN
REFERENCE ASSEMBLY BankingADLDB.[Newtonsoft.Json];
REFERENCE ASSEMBLY BankingADLDB.[Microsoft.Analytics.Samples.Formats];
USING Microsoft.Analytics.Samples.Formats.Json;
//These external parameters will be populated by ADF based on the time slice being executed.
DECLARE EXTERNAL @DateSliceStart DateTime =System.DateTime.Parse("2017/03/14");
DECLARE EXTERNAL @DateSliceEnd DateTime =System.DateTime.Parse("2017/03/14");
//These are intermediary variables which inherit the time element from the ADF time slice.
DECLARE @YearNbr int = @DateSliceStart.Year;
DECLARE @MonthNbr int = @DateSliceStart.Month;
DECLARE @DayNbr int = @DateSliceStart.Day;
//These are used to align the Year/Month/Day partitioning of the input & output.
//This technique also allows U-SQL to dynamically generate different output file path & name.
DECLARE @YearString string = @YearNbr.ToString();
DECLARE @MonthString string = @MonthNbr.ToString().PadLeft(2, '0');
DECLARE @DayString string = @DayNbr.ToString().PadLeft(2, '0');
DECLARE @InputPath = "/ATMMachineData/RawData/" + @YearString + "/" + @MonthString + "/{filename}.json";
DECLARE @OutputFile string = "/ATMMachineData/StandardizedData/" + @YearString + "/" + @MonthString + "/" + @YearString + @MonthString + @DayString + ".csv";
@RawData =
EXTRACT
[AID] string
,[Timestamp] DateTime
,[Data] string
,date DateTime//virtual column
,filename string//virtual column
FROM @InputPath
USING new JsonExtractor();
@CreateJSONTuple =
SELECT
[AID] AS AssignedID
,[Timestamp] AS TimestampUtc
,JsonFunctions.JsonTuple([Data]) AS EventData
FROM @RawData
WHERE [Timestamp] >= @DateSliceStart
AND [Timestamp] <@DateSliceEnd;
@Dataset =
SELECT
AssignedID
,TimestampUtc
,EventData["Val"] ?? "0" AS DataValue
,EventData["PrevVal"] ?? "0" AS PreviousDataValue
,EventData["Descr"] ?? "N/A" AS Description
FROM @CreateJSONTuple;
OUTPUT @Dataset
TO @OutputFile
USING Outputters.Csv(outputHeader:true,quoting:false);
END;
Step 2: Test the ADLA Procedure Works
Before we invoke it with ADF, let's double check our new procedure is working ok. Run the following U-SQL job in ADLA to call the procedure & use 3/14/2017 as the variable values (which matches the timestamp of our original source file):
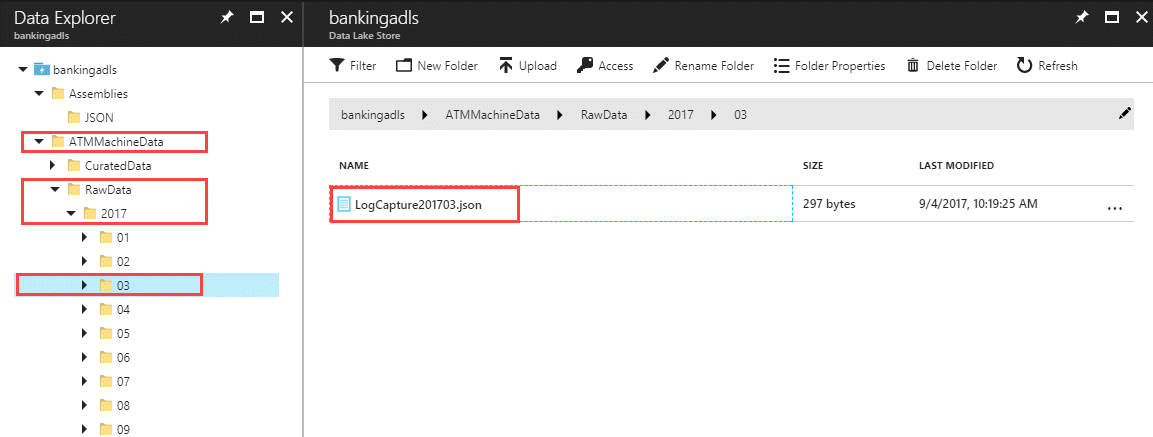
BankingADLDB.dbo.uspCreateStandardizedDataset(System.DateTime.Parse("2017/03/14"), System.DateTime.Parse("2017/03/15"));Verify the output is created via Data Explorer. Note the procedure will create the folder structure as well as the file based on the @OutputFile parameter value. After you have confirmed that it worked, go ahead & delete the output file ATMMachineData\StandardizedData\2017\03\20170314.csv so we can be certain later when it's been generated with ADF.

Step 3: Create a Service Principal For Use by ADF When it Executes U-SQL
You can authenticate using your own credentials in ADF, but they'll expire pretty quick -- so although that technique is fast and easy for testing, personal credentials won't work for ongoing scheduling. Therefore, we'll set this up using a service principal so you get started on the right foot. This is easiest in PowerShell (though you can also do this in the Azure portal if you prefer, in the Azure Active Directory menu > App Registrations page).
#Input Area $subscriptionName = '<YourSubscriptionNameHere>' $aadSvcPrinAppDisplayName = 'ADF ReadWrite Access To ADL - Svc Prin - Dev' $aadSvcPrinAppHomePage = 'http://ADFReadWriteAccessToADLDev' $aadSvcPrinAppIdentifierUri = 'https://url.com/ADFReadWriteAccessToADLDev' $aadSvcPrinAppPassword = '<YourComplicatedPWForAppRegistration>' #----------------------------------------- #Manual login into Azure Login-AzureRmAccount -SubscriptionName $subscriptionName #----------------------------------------- #Create Service Principal (App Registration): $aadSvcPrinApplicationDev = New-AzureRmADApplication ` -DisplayName $aadSvcPrinAppDisplayName ` -HomePage $aadSvcPrinAppHomePage ` -IdentifierUris $aadSvcPrinAppIdentifierUri ` -Password $aadSvcPrinAppPassword New-AzureRmADServicePrincipal -ApplicationId $aadSvcPrinApplicationDev.ApplicationId
In AAD, it should look like this:

I put "Dev" in the suffix of mine because I typically create separate service principals for each environment (Dev, Test, Prod). It's also frequently a good idea to create separate registrations for Read/Write vs. just Read permissions.
Step 4: Assign Permissions to the Service Principal So It Can Read and Write Via the ADF Job
For this step we'll use the portal instead of PowerShell. You can do this piece in PowerShell as well if you prefer using the Set-AzureRmDataLakeStoreItemAclEntry cmdlet - you'll also need to make sure the Azure Data Lake provider is registered. To keep this fast & easy, let's just use the portal.
Security for Azure Data Lake Store
The first piece is referred to as ACLs - access control lists. Go to Data Explorer in ADLS. Make sure you're on the root folder and select Access (or if you want to define permissions at a sub-foldere level only, it's ok to start from that level). Choose Add.

Select User or Group: choose the ADF service principal we just created.
Select Permissions: This account needs to read, write, and execute. Note the radio button selections as well so that existing and new child objects will be assigned this permission.

As soon as you hit ok, notice the message at the top of the page. Make sure not to close the blade while it's assigning the permissions to the child objects:

When you see that it's finished (with the green check mark), then it's ok to close the blade:

Security for Azure Data Lake Analytics
The second piece of security needed for our service principal is done over in Azure Data Lake Analytics, so that it's allowed to run U-SQL:

Note that the equivalent IAM (Identity & Access Mgmt) permissions for our service principal don't need to be assigned over in ADLS - just ADLA. Normally that step would be needed for a regular user though. There's actually a *lot* more to know about security with Azure Data Lake that I'm not going into here.
Step 5: Obtain IDs Needed for Azure Data Factory
AAD Application ID
Go find the Application ID for your new service principal and copy it so you have it:

Tenant ID (aka Directory ID)
Also find your Tenant ID that's associated with Azure Active Directory:

Subscription ID
And, lastly, find the Subscription ID where you've provisioned ADL and ADF:

Step 6: Create Azure Data Factory Components
The following ADF scripts include two linked services, two datasets, and one pipeline.
In both linked services you will need to replace several things (as well as the account name and resource group name). Also, be sure NOT to hit the authorize button if you're creating the linked services directly in the portal interface (it's actually a much better idea to use Visual Studio because all of these files can be source-controlled and you can use configuration files to direct deployments to Dev, Test, and Prod which have different values for IDs, keys, etc). You may also want to change the linked services names - mine is called lsBankingADLA (or S) to coincide with what my actual services are called -- but without the Dev, Test, Prod suffix that they have for real (because we need to propagate the linked services without changing the names).
Linked Service for Azure Data Lake Analytics
{
"name": "lsBankingADLA",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<YourADLAName>",
"dataLakeAnalyticsUri": "azuredatalakeanalytics.net",
"servicePrincipalId": "<YourApplicationIDForTheServicePrincipal>",
"servicePrincipalKey": "<YourComplicatedPWForAppRegistration>",
"tenant": "<YourAADDirectoryID>",
"subscriptionId": "<YourSubscriptionID>",
"resourceGroupName": "<YourResourceGroupWhereADLAResides>"
}
}
}
Linked Service for Azure Data Lake Store
{
"name": "lsBankingADLS",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "adl://<YourADLSName>.azuredatalakestore.net/",
"servicePrincipalId": "<YourApplicationIDForTheServicePrincipal>",
"servicePrincipalKey": "<YourComplicatedPWForAppRegistration>",
"tenant": "<YourAADDirectoryID>",
"subscriptionId": "<YourSubscriptionID>",
"resourceGroupName": "<YourResourceGroupWhereADLSResides>"
}
}
}Dataset for the Raw JSON Data
{
"name": "dsBankingADLSRawData",
"properties": {
"published": false,
"type": "AzureDataLakeStore",
"linkedServiceName": "lsBankingADLS",
"typeProperties": {
"fileName": "{year}/{month}/{day}.json",
"folderPath": "ATMMachineData/RawData/",
"format": {
"type": "JsonFormat"
},
"partitionedBy": [
{
"name": "year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
}
]
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": true,
"policy": {}
}
}
Dataset for the Standardized CSV Data
{
"name": "dsBankingADLSStandardizedData",
"properties": {
"published": false,
"type": "AzureDataLakeStore",
"linkedServiceName": "lsBankingADLS",
"typeProperties": {
"fileName": "SpecifiedInTheUSQLProcedure.csv",
"folderPath": "ATMMachineData/StandardizedData/{year}/{month}",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"nullValue": "N/A",
"firstRowAsHeader": true
},
"partitionedBy": [
{
"name": "year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
}
]
},
"availability": {
"frequency": "Day",
"interval": 1,
"anchorDateTime": "2017-03-14T00:00:00Z"
}
}
}Pipeline with U-SQL Activity to Run the Procedure in ADLA
{
"name": "plStandardizeBankingData",
"properties": {
"description": "Standardize JSON data into CSV, with friendly column names & consistent output for all event types. Creates one output (standardized) file per day.",
"activities": [
{
"type": "DataLakeAnalyticsU-SQL",
"typeProperties": {
"script": "BankingADLDB.dbo.uspCreateStandardizedDataset(System.DateTime.Parse(@DateSliceStart), System.DateTime.Parse(@DateSliceEnd));",
"degreeOfParallelism": 30,
"priority": 100,
"parameters": {
"DateSliceStart": "$$Text.Format('{0:yyyy-MM-ddTHH:mm:ssZ}', SliceStart)",
"DateSliceEnd": "$$Text.Format('{0:yyyy-MM-ddTHH:mm:ssZ}', SliceEnd)"
}
},
"inputs": [
{
"name": "dsBankingADLSRawData"
}
],
"outputs": [
{
"name": "dsBankingADLSStandardizedData"
}
],
"policy": {
"timeout": "06:00:00",
"concurrency": 10,
"executionPriorityOrder": "NewestFirst"
},
"scheduler": {
"frequency": "Day",
"interval": 1,
"anchorDateTime": "2017-03-14T00:00:00Z"
},
"name": "acStandardizeBankingData",
"linkedServiceName": "lsBankingADLA"
}
],
"start": "2017-03-14T00:00:00Z",
"end": "2017-03-15T00:00:00Z",
"isPaused": false,
"pipelineMode": "Scheduled"
}
}
A few comments about the pipeline:

Once all 5 components are deployed, they should look like this:

Step 7: Verify Success of ADF Job
We can verify the ADF job succeeded by looking at the Monitor & Manage App (note you'll have to set the start time back to March 2017 for it to actually show any activity windows):
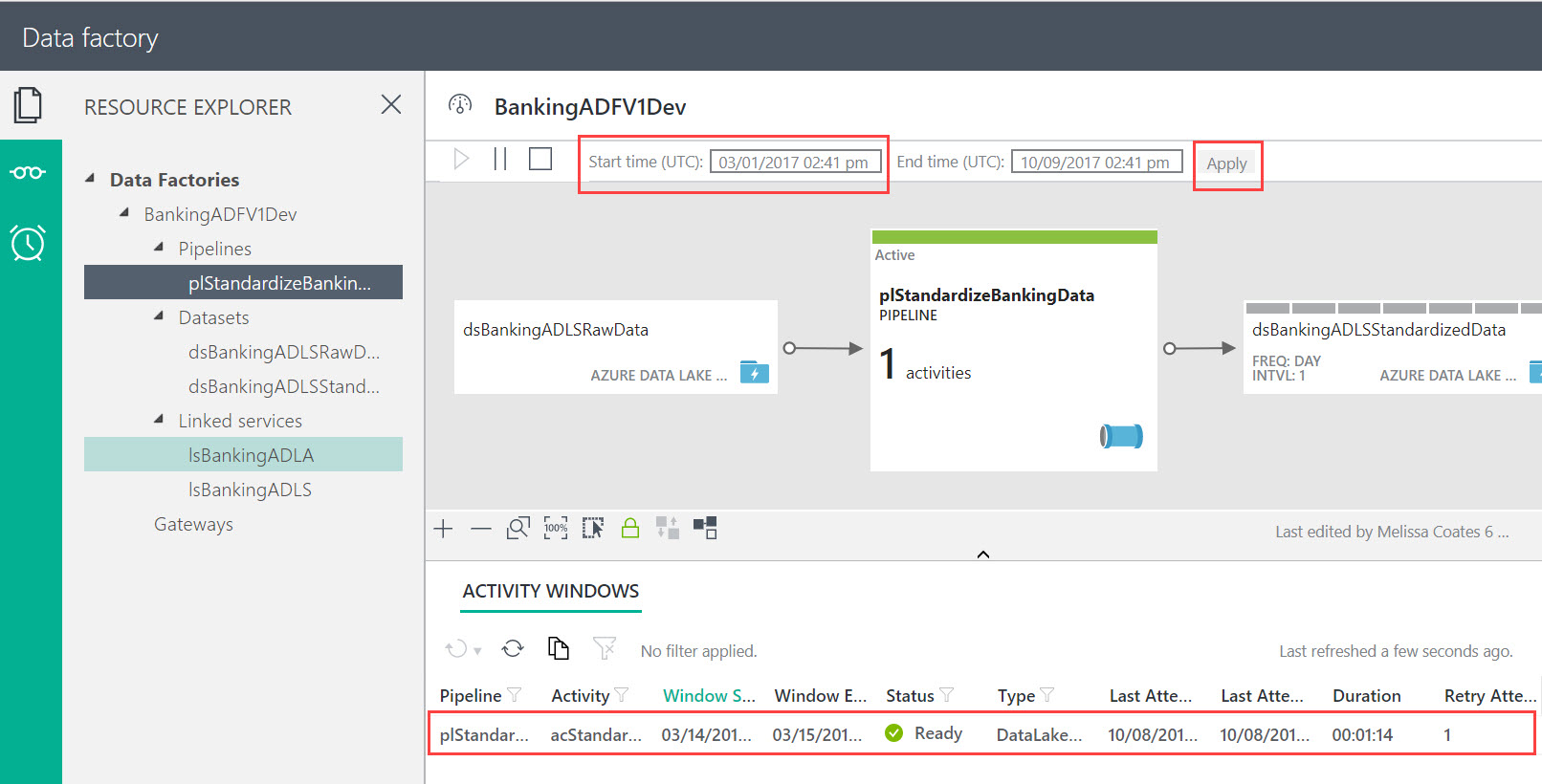
We can also see in the ADLA Job Management area that an ADF job was executed (it very kindly prefixes jobs run by Data Factory with ADF):

Whew. That's it. This same technique will continue to work with various files across dates (though I kept it to just one input file to keep this already-super-duper-long-post as straightforward as possible).
Want to Know More?
My next all-day workshop on Architecting a Data Lake is in Raleigh, NC on April 13, 2018.