The Azure AI Gallery (formerly known as the Cortana Intelligence Gallery) is a site where you can search for solutions, tutorials, experiments, and training for learning the data & analytics tools within Azure. The Gallery can be located at: https://gallery.cortanaintelligence.com/.
The Azure AI Gallery is a community site. Many of the contributions are from Microsoft directly. Individual community members can make contributions to the Gallery as well.
The "Solutions" are particularly interesting. Let's say you've searched and found Data Warehousing and Modern BI on Azure:
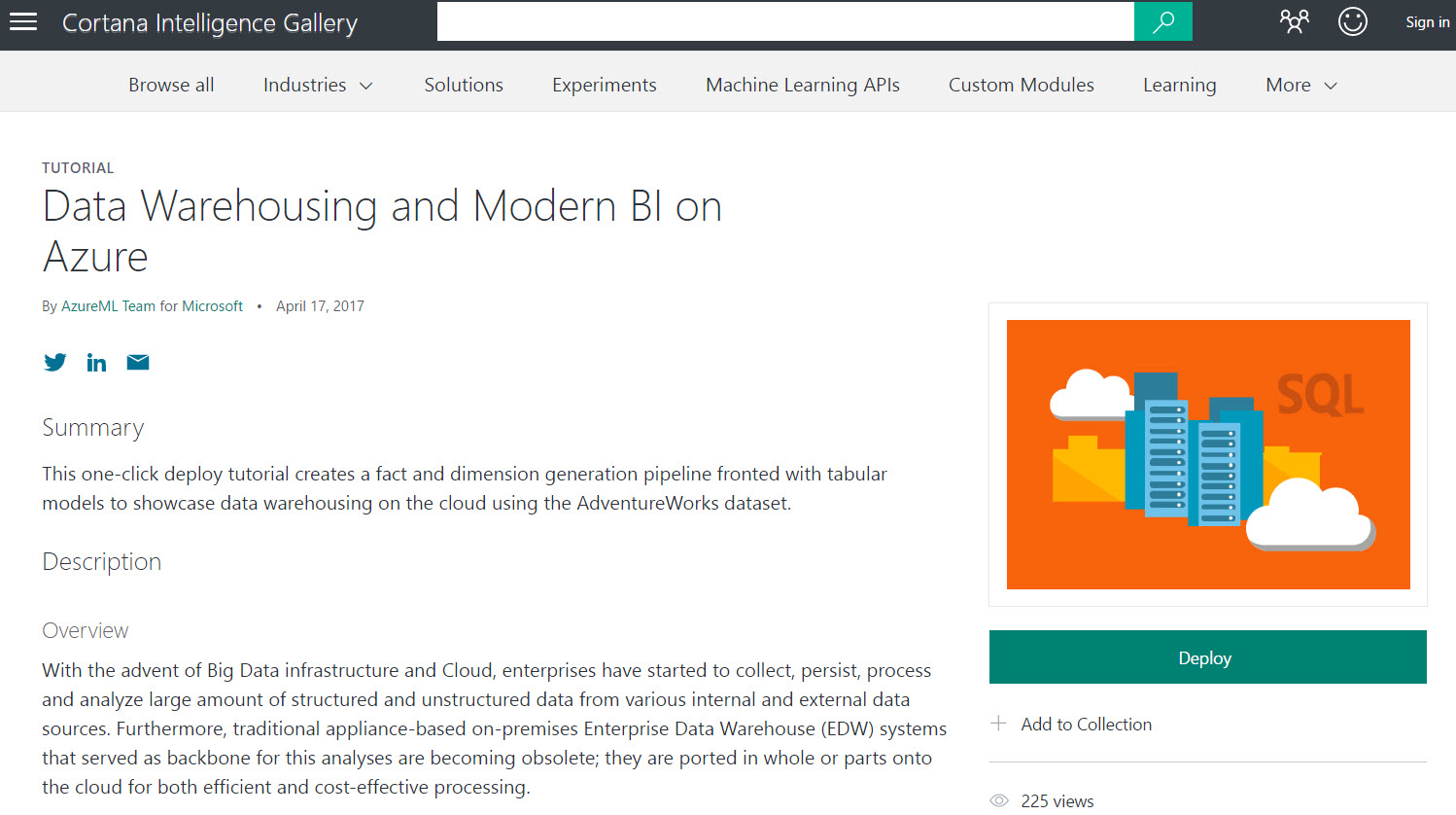

Deploying a Solution from the Azure AI Gallery
What makes these solutions pretty appealing is the "Deploy" button. They're packaged up to deploy all (or most) of the components into your Azure environment. I admit I'd like to see some fine-tuning of this deployment process as it progresses through the public preview. Here's a quick rundown what to expect.
1|Create new deployment:
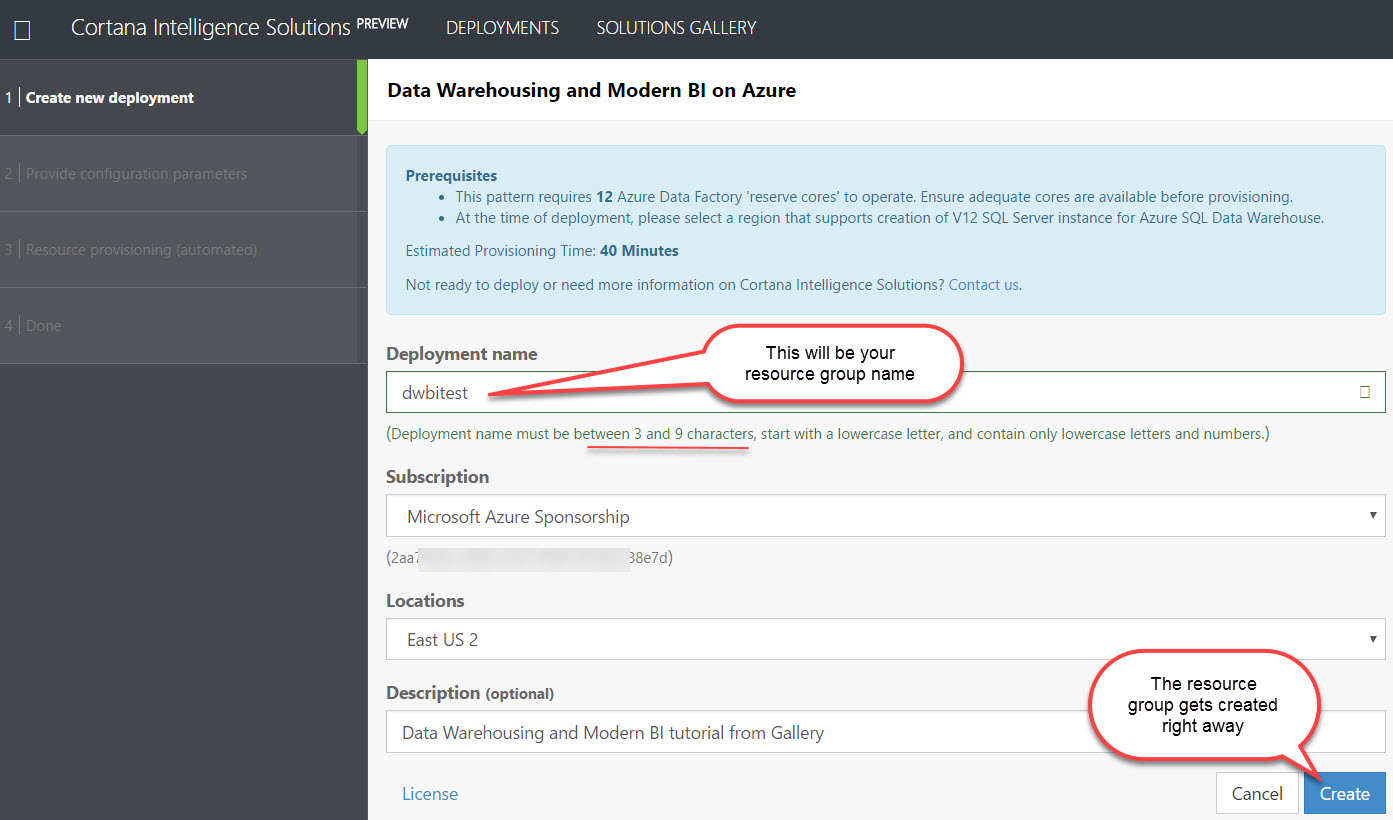
The most important thing in step 1 above is that your deployment name ends up being your resource group. The resource group is created as soon as you click the Create button (so if you change your mind on naming, you'll have to go manually delete the RG). Also note that you're only allowed 9 characters, which makes it hard to implement a good naming convention. (Have I ever mentioned how fond I am of naming conventions?!?)
Resource groups are an incredibly important concept in Azure. They are a way to logically organize related resources which (usually) have the same lifecycle and are managed together. All items within a single resource group are included in an ARM template. Resource groups can serve as a boundary for security/permissions at the RG level, and can be used to track the cost of a solution. So, it's extremely important to plan out resource group structure in your real environment. In our situation here, having all of these related resources for testing/learning purposes is perfect.
2|Provide configuration parameters:

In step 2 above, the only thing we need to specify is a user and password. This will be the server admin for both Azure SQL Database and Azure SQL Data Warehouse which are provisioned. It will use SQL authentication.
As soon as you hit the Next button, the solution is provisioning.
3|Resource provisioning (automated):

In step 3 above we see the progress. Depending on the type of resource, it may take a little while.
4|Done:
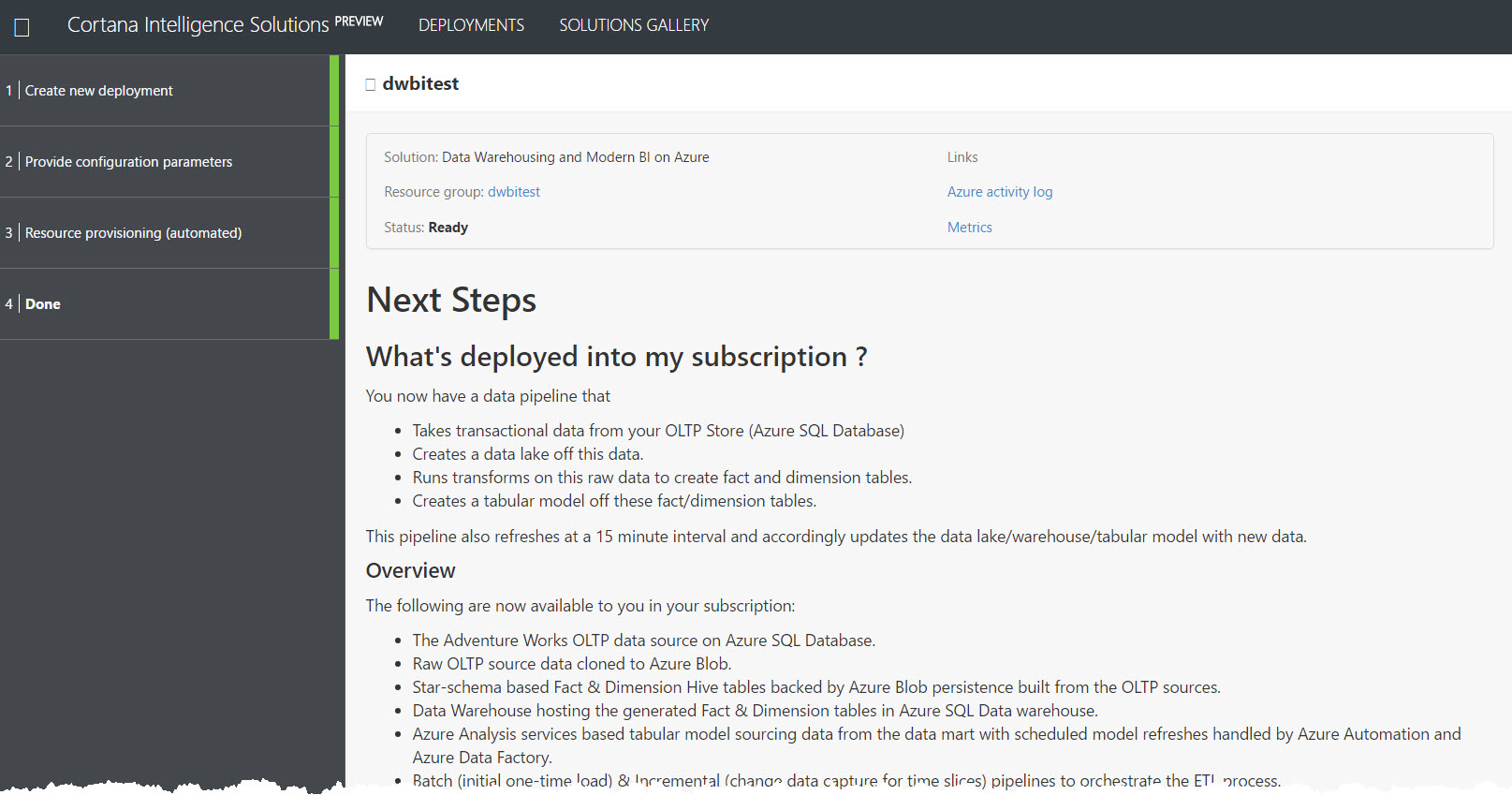
When provisioning is complete, as shown in step 4 above (partial screenshot), you get a list of what was created and instructions for follow-up steps. For instance, in this solution our next steps are to go and create an Azure Service Principal and then create the Azure Analysis Services model (via PowerShell script saved in an Azure runbook provided by the solution).
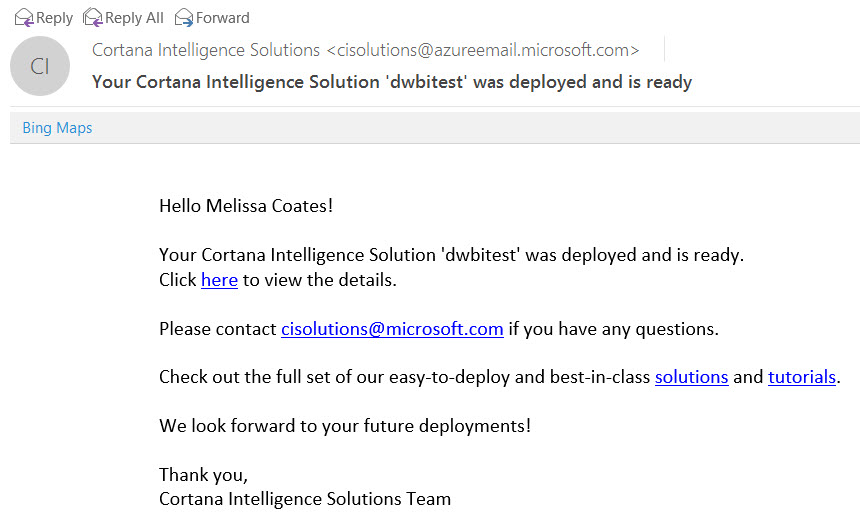
They also send an e-mail to confirm the deployment:
If we pop over to the Azure portal and review what was provisioned so far, we see the following:

We had no options along the way for selecting names for resources, so we have a lot of auto-generated suffixes for our resource names. This is ok for purely learning scenarios, but not my preference if we're starting a true project with a pre-configured solution. Following an existing naming convention is impossible with solutions (at this point anyway). A wish list item I have is for the solution deployment UI to display the proposed names for each resource and let us alter if desired before the provisioning begins.
The deployment also doesn't prompt for which subscription to deploy to (if you have multiple subscriptions like I do). The deployment did go to the subscription I wanted, however, it would be really nice to have that as a selection to make sure it's not just luck.
We aren't prompted to select scale levels during deployment. From what I can tell, it chooses the lowest possible scale (I noted that the SQL Data Warehouse was provisioned with 100 DWUs, and the SQLDB had 5 DTUs).
To minimize cost, don't forget to pause what you can (such as the SQL Data Warehouse) when you're not using it. The HDInsight piece of this will be the most expensive, and it cannot be paused, so you might want to learn & experiment with that first then de-provision HDInsight in order to save on cost. If you're done with the whole solution, you can just delete the resource group (in which case all resources within it will be deleted permanently).
Referring to Documentation for Deployed Solutions
You can find each of your deployed solutions here: https://start.cortanaintelligence.com/Deployments.

From this view, you can refer back to the documentation for a solution deployment (which is the same info presented in Step 4 when it was finished provisioning).
You can also 'Clean up Deployments' which is a nice feature. The clean up operation first deletes each individual resource, then it deletes the resource group:

That's it. Have fun learning and testing.