
This post covers several things I've heard or been asked recently about organizing data in a data lake.
Q: Partitioning by date is common. Where should the dates go in the folder hierarchy?
Almost always, you will want the dates to be at the end of the folder path. This is because we often need to set security at specific folder levels (such as by subject area), but we rarely set up security based on time elements.
Optimal for folder security: \SubjectArea\DataSource\YYYY\MM\DD\FileData_YYYY_MM_DD.csv
Tedious for folder security: \YYYY\MM\DD\SubjectArea\DataSource\FileData_YYYY_MM_DD.csv
Here’s an example of what the raw data zone might look like with the date partitioning at the end:
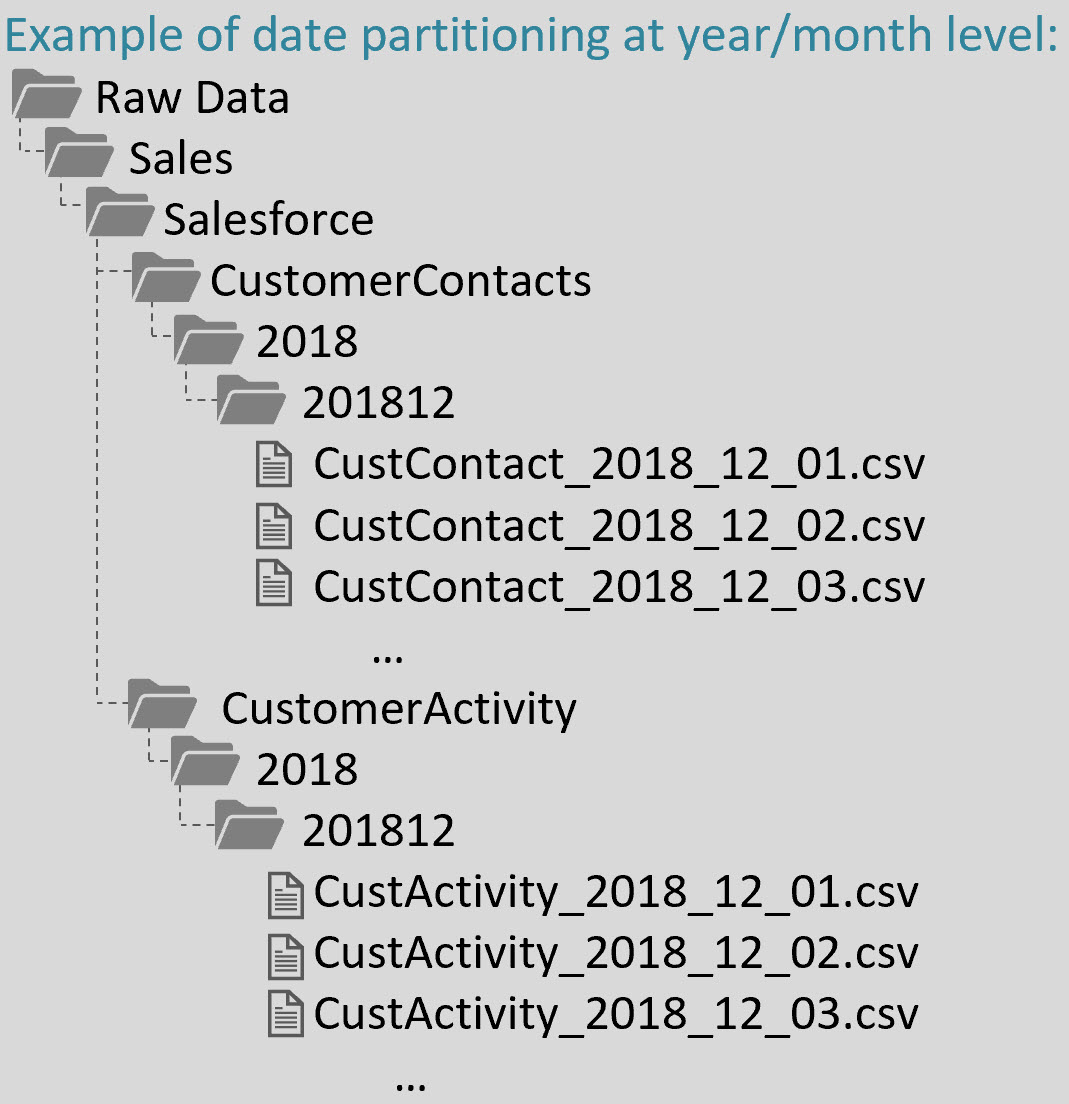
Notice in the above example how the date element is repeated in *both* the folder structure and the file name. Being very clear in the naming of folders and files helps a lot with usability.
Also, keep in mind that related compute engines or data processing tools might have a firm expectation as to what the folder structure is (or potentially is contained in the file name). For instance, the year and month folders might translate directly to a column within the file. Or, if you’re using a tool like Azure Stream Analytics to push data to the lake, you’ll be defining in ASA what the date partitioning schema looks like in the data lake (because ASA takes care of creating the folders as data arrives).
Q: How do data lake zones translate to a folder structure?
The zones that I talked about previously are a conceptual idea. Most commonly I’ve seen zones translate to a top level folder (like shown in the image above). However, it's also possible that the zones would reside within, say, a subject area as shown in this next image:

Generally speaking, business users only get access to the prepared data in the curated data zone (with some exceptions of course). Zones like Raw Data and Staged Data are frequently ‘kitchen areas’ that have little to no user access. That’s why putting the zones at the top-most level is very common. However, if your objective is to make all of the data available in an easier way, then putting zones underneath a subject area might make sense—this is less common from what I’ve seen though because exposing too much data to business users can be confusing.
On the flip side, another less common option would be to further separate zones beyond just top-level folders. For instance, in Azure Data Lake Storage Gen 2, we have the structure of Account > File System > Folders > Files to work with (terminology-wise, a File System in ADLS Gen 2 is equivalent to a Container in Azure Blob Storage). Depending on what you are trying to accomplish, you might decide that separate file systems are appropriate for areas of your data lake:
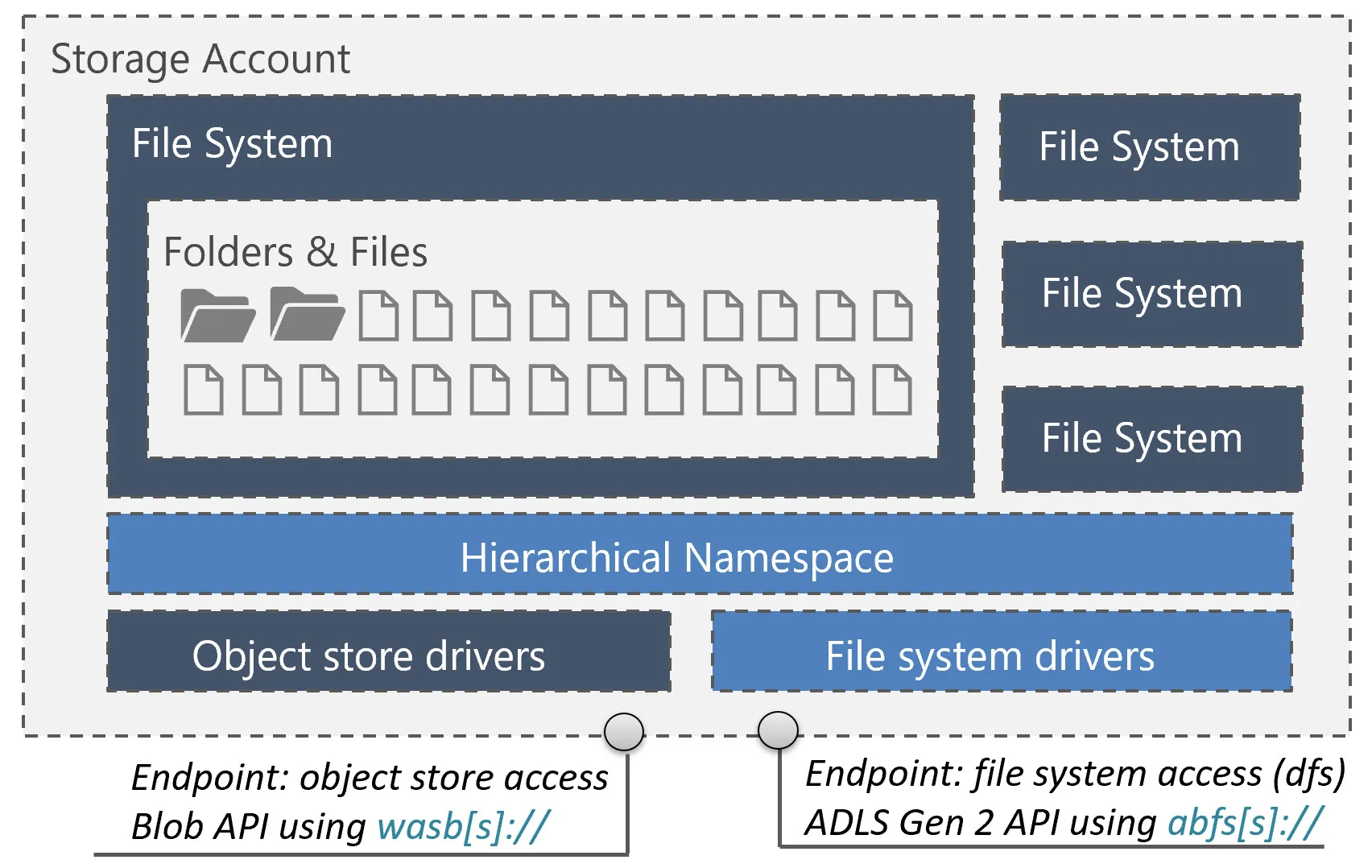
If your objective is to have an enterprise-wise data lake, then more separation is less appealing.
Q: Should the date reflected in the folder structure be the ingestion date or the date associated with the source data?
It could be either one. I tend to think this is dependent on whether you're dealing with data that's being pushed or pulled into the data lake, and if it’s transactional or snapshot data.
Push system: Let’s say you have machine telemetry or IoT data that is being loaded to the data lake. In this case, the dates in the folder structure would typically be based on ingestion date.
Pull system: If you have a scheduled process that loads data into the lake, then it's up to the architect of the process to determine what the date means:
Transactional data: If sales data is being loaded, the dates could easily relate to the sale transaction date (even if we pulled the data out three days later). Typically transactional data is append-only.
Snapshot data: Let’s say we want to organize the data by its "as of" date. If you look back at the very first image shown above, the CustomerContacts folder is intended to show a snapshot of what that data looked like as of a point in time. Typically this would be for reference data, and is stored in full every time it’s extracted into the data lake.
Q: Is it a good idea to created folders which nest multiple data elements?
This type of structure which nests 3 data elements into 1 folder is typically *not* recommended:

There are two potential issues with ‘nesting’ elements like Company-Division-Project as shown above:
Security: Setting up security is probably harder. For instance, if Mary should see everything in Division 2, that just got harder because now Division is associated with the granularity of Projects. Not impossible to manage, just likely to be more work.
Performance: The query performance can suffer. Some compute engines & query tools can understand the structure of the data lake and do ‘data pruning’ (like predicate pushdown). Let’s say you send a query asking for all data for Project A240. If Project were its own folder, the likelihood of the compute engine needing to scan only that one folder is much higher and would improve performance considerably. (This performance optimization is applicable to a hierarchical file system like Azure Data Lake Storage (Gen1 or Gen2), but not applicable to an object store like Azure Blob Storage.)
Q: If I need a separate dev, test, prod environment, how would this usually be handled?
Usually separate environments are handled with separate services. For instance, in Azure, that would be 3 separate Azure Data Lake Storage resources (which might be in the same subscription or different subscriptions).
We wouldn’t usually separate out dev/test/prod with a folder structure in the same data lake. It can be done (just like you could use the same database with a different schema for dev/test/prod) but it’s not the typical recommended way of handling the separation. We prefer having the exact same folder structure across all 3 environments. If you must get by with it being within one data lake (one service), then the environment should be the top level node.
Q: How much do I need to be concerned with the similarity of file contents within a folder?
The general rule is for all files to have the same format underneath a folder node. This is because scripts often traverse all files in a folder. If you have something like JSON it's fine if the schema differs per file, but for fixed data structures such as CSV, a script will error out if some of the files have a different format. (This does mean sometimes you need to refresh historical files to align with a format change that occurred along the way.)
Q: When should we load data from a relational data source into a data lake?
I devoted a blog post to this because it comes up a lot—check here.
Q: Data lakes are supposed to be agile. So I don’t need to worry about about naming conventions, right?
Try your best to not neglect naming conventions. You might use camel case, or you might just go with all lower case – either is ok, as long as you’re consistent. There are two big reasons for this: First, some languages are case-sensitive so consistent naming structures end up being less frustrating. Second, the bigger your data lake gets the more likely you are to have scripts that manage the data and/or the metadata, and they are more easily maintained and parameterized if consistent.
You Might Also Like…
When Should We Load Relational Data to a Data Lake?
Data Lake Use Cases and Planning Considerations
BlueGranite eBook - Data Lakes in a Modern Data Architecture